intjonathan
Kubernetes the Database
by Jonathan Owens
Notes
A talk given with Maryum Styles at KubeCon + CloudNativeCon 2018 in Seattle, WA.
We were working on a team operating a Mesos cluster and needed more advanced inventory and orchestration tools than Mesos could provide. We created a Kubernetes API server cluster with custom resources, along with inventory software to populate objects based on AWS and datacenter inventory. With the broad client support for first-class operation locking and object inventory in the Kubernetes ecosystem, we could accelerate our cluster management tooling dramatically.
I don’t like the title we ended up with. At the time I imagined Yogurt from Spaceballs going through his merchandise (“Spaceballs the lunchbox, Spaceballs the flame thrower!”), sort of as a spin on how Kubernetes gets used for everything (“Kubernetes the webserver! Kubernetes the database!”). The pattern we’re describing is using the Kubernetes API server with custom resources as an inventory server for cloud and physical machines, along with describing and orchestrating cluster state. Perhaps a better title would be “Kubernetes Inventory for Non-K8s Resources”.
Video
Abstract
In the operations world, one of the hardest problems is keeping track of your inventory: Which machines belong to which teams? Which machines are in service? How long have they been there? At New Relic, the ability to keep track of a massive inventory that runs across multiple providers quickly became an unbearable task so much so that it required designing a completely new central tracking system that could scale with a large infrastructure. In this talk, you’ll learn how Jonathan Owens and Maryum Styles used the Kubernetes API server to jump-start this design and create a unified infrastructure description service. They will share how they defined resources, created controller services, and dramatically decreased the process of manual updates.
Article
This article was originally published on the New Relic blog. See an archival copy on the wayback machine.
In the operations world, inventory management is an unglamorous but essential task that answers basic questions: Which machines belong to which teams? Which machines are in service? How long have they been there? Getting useful answers to these questions, however, can be a struggle—especially when a team operates in a dynamic and rapidly scaling environment.
This is exactly the situation New Relic’s container orchestration team—known internally as Container Fabric—recently faced. Our solution, which leverages the Kubernetes API server and support for custom resource definitions, gives us a far more robust and scalable way to handle inventory management—and as we’ll explain, the same capabilities are useful for a number of other applications, as well.
The challenge: staying ahead of an expanding fabric
The New Relic Container Fabric team builds and maintains the company’s internal platform for deploying and maintaining containerized services. Our developers push code from their laptops in containers, and we run those containers on our platform.
The environment this team manages isn’t massive by modern enterprise standards, but it’s large and growing rapidly. We currently manage about 1,000 machines, most of which run on physical hardware spread across three infrastructure providers, including our own bare-metal data center. In addition, we recently expanded our infrastructure with a dedicated European region—a necessary move that added a new source of complexity.
As the Container Fabric platform grows, our current approach to inventory management is likely to create an operational bottleneck. Operating across multiple regions, for example, has increased the number of secure network connections our orchestration services must traverse.
To create a single source of truth for our orchestration services, we used the Kubernetes API server’s custom object definition capabilities to devise a new inventory management solution. It’s more efficient and far more scalable—allowing Container Fabric to grow along with the rest of New Relic. Better still, this solution is based on familiar technology—and we have already found ways to leverage the same technology for other applications.
The trouble with inventory at scale
The Container Fabric software environment currently runs on Mesosphere DC/OS: an open-source, distributed operating system, built with Apache Mesos, that uses Marathon to provide container orchestration services.
Container Fabric was developed prior to Kubernetes’ emergence into the mainstream. We selected DC/OS at a time when it was the most stable and reliable option for our needs, and it has served us well for running services. Managing DC/OS itself, however, has not been so easy. As a result, The Container Fabric team is planning a migration to Kubernetes.
Our previous approach to inventory management used Ansible and Terraform to define, enumerate, configure, and manage our infrastructure. Setting up a new machine involved a Terraform run, which requested provisioning from one of our infrastructure providers. Once the provider created the machines we requested, we used Ansible again to ask the providers to communicate back to us the same resource that we had just asked Terraform for; then we asked the host to put it into service.
This process required total network connectivity across the components. The Ansible instance that handled orchestration, for example, connected over a VPN to communicate with the infrastructure provider, and it used the same VPN to communicate with the new machines to put them to work.
Finally, as noted, we added a new European region last year. This added a new set of networking requirements—including another VPN—and thus an additional layer of complexity. We were particularly concerned about the increasingly complex networking requirements we faced as Container Fabric continued to scale across a multi-region architecture.

We soon realized, however, that the real challenge Container Fabric faced wasn’t a connectivity problem so much as an inventory problem. What we needed was current data about our machines—names, locations, states—to maintain an always up-to-date picture of what was happening “on the ground” in our infrastructure. Then, if needed, orchestration could make the appropriate VPN connection to access a region and cluster to update machine configuration. Knowing what was happening, and where it was happening, was the key to reducing toil as we grew.
Searching for solutions
At this point, we set about looking for solutions to our inventory problem. The first three options, in our opinion, were fatally flawed.
Option 1: Create a solution using Terraform state data. Most Terraform users are familiar with the “terraform.tfstate” file: a custom JSON format file that records a mapping from the Terraform resources in your templates to the representation of those resources in the real world. We assessed this Terraform state intelligence as the basis for a distributed and scalable inventory management solution, but we identified at least two deal-breaking drawbacks to this approach.
- First, the file itself updates only in response to an on-demand event, such as a Terraform plan or refresh command. It’s not a real-time reflection of the infrastructure.
- Second, since we’re dealing with a simple, static text file, every update, no matter how small, would have required a full rewrite of the file. This increased the risk that multiple clients could stomp on each other when trying to perform updates.
Option 2: Buy a commercial DCIM solution. We evaluated several data center infrastructure management (DCIM) solutions, such as Device42. These are tailored to organizations running their own data centers—certainly, we fit that target market.
DCIM offerings excel at answering questions that ask, essentially, “Where’s my stuff? Where’s a particular machine? What rack is it in? What are the PDUs? How many HDDs do you have on hand?” Such offerings are less effective, however, at defining and managing the kinds of higher-level abstractions (e.g. clusters and regions) that we need in an inventory-management solution.
Option 3: Adapt DC/OS to address inventory management. Finally, we looked at DC/OS itself to identify any potentially useful capabilities that we could harness for an inventory solution. Unfortunately, DC/OS isn’t built for this type of work—Mesos, the technology at the center of it, is architected for a more responsive pattern. Mesos doesn’t maintain a “desired state” for the machines in a cluster, or even for the services on a machine.
It’s worth noting that DC/OS includes Apache Zookeeper, a distributed information service, and etcd, a distributed key value store, as part of its default installation. We considered using these services to implement the capabilities we were looking for. The resulting solution, however, wouldn’t have worked with higher-level abstractions, and it wouldn’t offer benefits that we couldn’t get from deploying our own installation of these services.
Important lessons learned
Although our initial search failed to find an acceptable inventory management solution for us, it did help us define the requirements and capabilities we needed:
- A single source of information for inventory management. No longer would we need to split code paths based on infrastructure providers.
- The ability to update from anywhere without having to stand up a VPN connection. This requirement was essential for all data centers.
- Compatibility with Ansible dynamic inventory. This was necessary since we were looking for a different inventory management solution, but we also wanted to keep our current approach to orchestration unchanged for the time being.
- Production-quality performance. This was an obvious need if we intended to extend the solution to monitoring and other functions beyond inventory management.
- Locally meaningful and extensible object representation. Specifically, we needed the ability to work with higher-level abstractions that took us beyond the “where’s my stuff?” questions that are the usual forte of DCIM solutions.
The fourth time’s the charm: landing on the Kubernetes API server
We were already familiar with Kubernetes, which is New Relic’s preferred container orchestration platform. What really put Kubernetes on our radar as an inventory management option was our realization that it has something DC/OS does not: an integral, centralized configuration service.
The kube-apiserver is one of the core components of a Kubernetes cluster; it holds the declarative state of all the objects that represent the cluster’s behavior. It ships with a library of predefined objects designed to streamline this process, including representations of deployments, stateful sets, services, and so on. The kube-apiserver, however, also supports custom resources. These resources are intended mostly to facilitate more complex application deployments. But there’s no reason why they can’t serve other functions.
In fact, we realized, kube-apiserver could meet all of our inventory management requirements. But first, we would have to create three additional components:
- A basic object structure—in practice, a blob of YAML—to define our custom resources for the kube-apiserver. This creates custom resource definition (CRD) objects (which we refer to as host objects), inside the server.
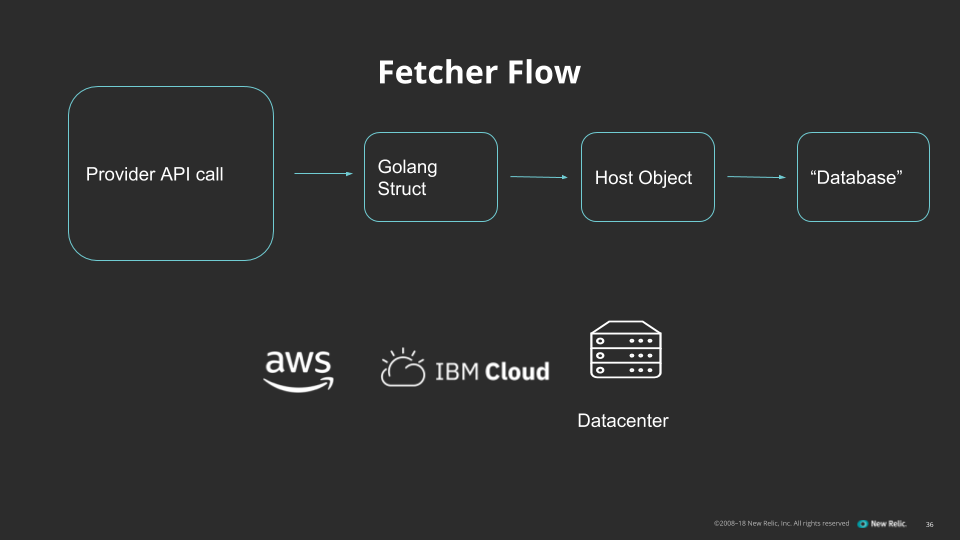
- A service that runs inside each infrastructure provider to enumerate the hosts we have running there and to send that list back to the kube-apiserver. This creates host objects in the kube-apiserver that represent individual machines running at a particular provider.
- A dynamic inventory script that lets Ansible communicate with the kube-apiserver and use host objects. The host objects will be populated via instances of what we refer to as a “fetcher”—a service that retrieves the required host data from a particular provider for use in our new inventory system.
Implementing our kube-apiserver solution
Our implementation process was simple—and much easier than a typical Kubernetes deployment. We weren’t actually deploying Kubernetes in the traditional sense; we use only kube-apiserver, along with the kube-controller-manager (for cert management) and etcd3 (for object storage). We weren’t deploying any pods or any workloads during this process, and we weren’t doing any pod networking. There was less to do and fewer ways for the process to go wrong.

That means our first step was following Kubernetes the hard way but stopping at step 8—or bootstrapping the Kubernetes control plane. This gave us a running kube-apiserver instance with which we could work. With that in hand, we wrote orchestration in our existing Terraform and Ansible toolchain to build more kube-apiserver instances for staging and production.
Next, we created CRDs for our host objects as YAML files, and we used kubectl apply to create them in the kube-apiserver.
Then we were ready to write some Go code to fetch host data from our providers and populate those host objects with data. This involved:
- Writing Go structs as representations of the host CRDs to use in our client code.
- Using the kubernetes code-generator to create Go client code that can perform create, read, update, and delete (CRUD) operations on those CRD objects.
- Finally, writing a block of fetcher code for each infrastructure provider that can translate their representation of a machine into our host.
The service loop for a fetcher looks like this:
- The fetcher queries the provider’s API for all the hosts we want to put in our inventory, typically filtered by tag.
- The provider’s API server responds with the list of our hosts. We convert this response into a Go struct compatible with the host CRD.
- We use the generated client libraries to update or create the host objects on the kube-apiserver with the updated data from the provider.
CRD and Go struct code examples
Here’s a shortened view of our host CRD in YAML:

This is what our host looks like in the form of a Go struct, which we use for internal development work:

The ObjectMeta stores the annotation and labels for the CRD itself. Spec represents the desired state of the host object, and Status represents its current state.
Labels and annotations are useful for tasks such as searching and filtering; for example, you can use the command line or an API request to see all hosts running as log machines on a specific provider’s infrastructure. We also use annotations to store data about the host that we can use in downstream configuration scripts.
Working with the solution

The full solution creates an infrastructure inventory database with endless expansion capability.
Of course, for a database to be useful, you need clients, which for this project means an Ansible dynamic inventory script. Ours is in Python, as most are, and uses the Kubernetes pip package for the kube-apiserver client.
The Kubernetes Python library returns a big dictionary of host objects from our kube-apiserver, which we transform into JSON output suitable for Ansible. We then use Ansible for our orchestration services as before.

Two reasons why kube-apiserver excels at scale
Adapting kube-apiserver to serve as an inventory-management database has a significant impact on our operational capabilities. We’re able to define declarative desired states for our cluster and to build cluster services in a decomposed way—clients of the kube-apiserver don’t need to know about each other, even when working on objects at the same time.
As a result, we’re no longer tied to a phased, manual, and highly iterative process with a lot of back-and-forth exchanges. We’re now far better prepared to operate at scale and to move with confidence into a multi-region future.
There are a couple of additional reasons why Kubernetes, and especially kube-apiserver, is well-suited for this role:
- Kubernetes supports the use of TLS mutual authentication. This lets us get rid of the VPNs, and the associated network connectivity requirements, that would have added more complexity at scale than we were prepared to accept.
- The kube-apiserver handles consistency ordering. If a client tries to make an update request to an object, but another server has already handled that change, kube-apiserver will notify that client. This makes it easier for us to make dynamic configuration changes—for example, deploying monitoring logic to new hosts as they’re configured—that previously would have required us to rely on some heavy lifting from git and Ansible.
A solution that’s ready for the future
As mentioned earlier, it’s easy to envision other applications for our kube-apiserver based inventory management solution. In fact, we’ve already built a polling system for generating monitoring configuration out of our inventory. As the hosts in our fleet change, we need to dynamically build or destroy monitoring for each host. This used to require a git commit to add the hostname every time a host in the fleet changed. Now, we don’t even think about it—our monitoring server subscribes to changes in the host objects and generates alert configuration on its own.
We took this even further and built a change orchestration system for running Ansible. Starting from a daemon process on each host that monitors its own host CRD record, we can start putting fields into the spec stanza of each host that the daemon can respond to: triggering Ansible runs on its own, moving the host in and out of maintenance, or upgrading the operating system. Having one authoritative, universally accessible place for desired host state was the foothold we needed to radically change our day-to-day operations with software.
This approach has also been a great starting point for our longer-term plans to migrate from DC/OS to Kubernetes—a journey that many other operations teams are planning, as well.
tags: